ITU-ledet forskningsprojekt vil forbedre kvaliteten af maskinoversættelser
Ifølge lektor på IT-Universitet Leon Derczynski kan Danish Gigaword Project forbedre kvaliteten af alt fra maskinoversættelse til opsporing af fake news på dansk.
Skrevet 4. juni 2021 08:31 af Theis Duelund Jensen
I den moderne verden bruger vi computere hver dag til at bearbejde tekst og sprog, men sammenlignet med mennesker, har computere brug for større mængder data for at forstå et sprog, og den data er ikke lige tilgængelig blandt alle sprogområder. Hvad betyder det helt konkret? Lad os illustrere pointen med et eksempel fra Google Translate:
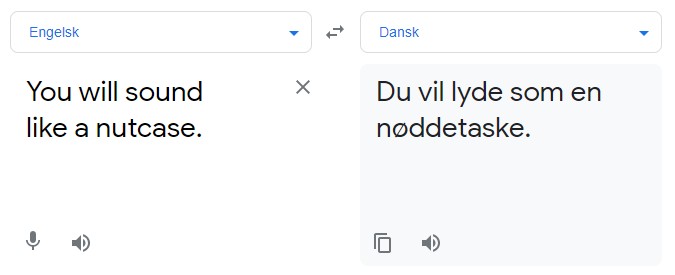
I stedet for at lyde som en ”galning”, lyder man pludselig som en ”nøddetaske”. Det er er der imidlertid en god forklaring på, for Google Translate arbejder med en model – en algoritme, der med datainput kan trænes til at foretage valg i en given proces fx i oversættelsen af en sætning – hvis data over det danske sprog er meget begrænset. Det er her, det ITU-ledede Danish Gigaword Project kommer ind i billedet.
Forskningsprojektet, der er anført af lektor på ITU Leon Derczynski og Manuel R. Ciosici fra University of Southern California, samler det første såkaldte gigaword datasæt (fordi det rummer over en milliard danske ord), der kan gøre en automatiseret oversættelsestjeneste som Googles langt mere træfsikker.
- Vi havde allerede et gigaword-datasæt til det engelske sprog for 30 år siden. Selv Islands 360.000 indbyggere har et gigaword-datasæt, der dækker deres sprog. Danmark er langt bagefter på området. Projektet er vigtigt, hvis vi vil have bedre kunstig intelligens, der kan forstå det danske sprog. Der er behov for store datasæt for at udvikle nye værktøjer, siger Leon Derczynski.
Det er netop målet med gigaword-projektet. Kort sagt og med terminologi lånt fra Natural Language Processing, opgraderer datasættet Dansk fra at være et såkaldt lavressource sprog til at være et højressource sprog. Det betyder, at vi kan forvente at se bedre maskinoversættelser, bedre talegenkendelse og mere præcise søgeresultater, så snart datasættet er i brug.
Mange bække små
Men hvad er et gigaword-datasæt helt præcist? Kort fortalt er det et enormt datasæt over det danske sprog, som det optræder i skriftlige kilder. For at sammensætte et datasæt, der indeholder samtlige nuancer og sproglige spidsfindigheder i skriftlig kommunikation på et givent sprog, er der imidlertid behov for mere end bare en masse data – der er behov for en masse data fra en masse forskellige kilder.
- Hvis man kun træner sine algoritmer med fx nyhedsartikler, så vil de kun være i stand til at forstå nyhedsartikler. Det kan være fint i visse sammenhænge, men det er de færreste af os, der kommunikerer med det samme sprog som DR eller Weekendavisen bruger. Vi udtrykker os meget forskelligt via skrift. Det var vigtigt i vores projekt, at vi fik så mange forskellige eksempler på Dansk med som muligt, fortæller Leon Derczynski, der startede projektet i 2019 og siden har ledet og koordineret arbejdet sammen med frivillige kræfter fra alle hjørner af det danske tech- og forskningsmiljø.
Den videnskabelige artikel om Danish Gigaword Project, som Leon Dercsynski og hans medforfattere netop har præsenteret ved Nordic Conference on Computational Linguistics, indeholder en liste over datakilder. I datasættet indgår bl.a. mødereferater og taler fra Folketinget, data fra et videnskabeligt projekt om spontan tale, Wikipedia-sider og en digital version af biblen.
Copyright-udfordringer
Det er dog lettere sagt end gjort at oprette et gigantisk sprogdatasæt, især hvis man arbejder i en dansk sammenhæng.
- En af de største barrierer for vores arbejde i Danmark er, at folk er langt mere forsigtige, når det handler om at dele data. I USA har The New York Times, Associated Press, Xinhua News Agency og Agence France-Presse samlet doneret artikler indeholdende en milliard ord til det engelske datasæt. Det er sværere i Danmark, fordi ophavsretten stiller andre krav. Det har været en kamp at sætte datasættet sammen og gøre det frit tilgængeligt. Det er netop vores overordnede mål, at det skal være frit tilgængeligt for forskere og virksomheder, så de kan udvikle nye teknologier, siger Leon Derczynski.
Selvom rettigheder har været en stor nød at knække, så er det lykkedes at skabe samarbejder med store danske medier om deling af sprogdata. Senest har Leon Derczynski skaffet projektet 50.000 artikler udgivet mellem 2010 og 2019 hos TV2 Regionerne.
- De store sprogmodeller, som man med jævne mellemrum ser omtalt i medierne i forbindelse med nye fremskridt inden for kunstig intelligens, taler og forstår kun engelsk. Det er virkelig ærgerligt, hvis man arbejder med fx dansk. Med det danske gigaword-datasæt kan vi nu træne langt mere avancerede modeller og sætte skub i teknologiudviklingen i Danmark.
Mere information:
Du kan læse mere om projektet på gigaword.dk
Theis Duelund Jensen, presseansvarlig, 2555 0447, thej@itu.dk